Strukturelle Klassifizierung von Proteinen und Naturstoffen für die Chemische Genomik
Forschungsbericht (importiert) 2005 - Max-Planck-Institut für molekulare Physiologie
Biologische Relevanz im chemischen Strukturraum
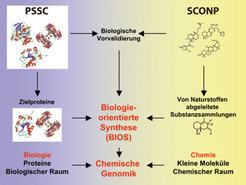
Der chemische Strukturraum, der von kleinen, wirkstoffartigen Molekülen umspannt wird, die für die Forschung in der chemischen Biologie und der medizinischen Chemie in Frage kommen, ist so groß, dass er durch organische Synthese nicht ausgelotet und ausgenutzt werden kann. Auch die Natur wird die Möglichkeiten bei der Synthese von Liganden für Proteine bei weitem nicht ausgeschöpft haben. Um effizient kleine Moleküle als Liganden für Proteine zu entwickeln, ist es daher entscheidend, biologische und chemische Methoden mit denen der Informatik zu koppeln. Nur so kann der biologisch relevante Strukturraum identifiziert und kartiert werden, das heißt die Regionen des gesamten chemischen Strukturraums, die für die Biologie und die Substanzentwicklung bedeutsam sind.
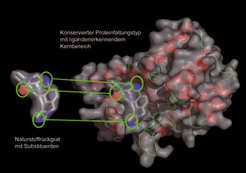
Eine Arbeitsgruppe um Herbert Waldmann am MPI in Dortmund hat Methoden entwickelt, die einerseits auf der Konservierung von Struktur in der Proteinwelt aufbauen, andererseits auf einer strukturellen Klassifizierung aller bekannten natürlichen Liganden von Proteinen beruhen. In diesem Ansatz bilden Kernbereiche, eingebettet in Proteinfaltungstypen, das strukturelle Rückgrat: Sie erkennen die in der Evolution konservierten Liganden. Durch unterschiedliche Aminosäure-Seitenketten wird die notwendige strukturelle Diversität erzeugt (Abb. 1).
Ziel ist es, diese Kernstrukturen von Proteinen nach rein strukturellen Gesichtspunkten zu analysieren und zu gruppieren und das mit einer strukturellen Klassifizierung und Gruppierung von Naturstoffen zu kombinieren. Dieses Vorgehen sollte zu Startpunkten im chemischen Strukturraum führen – für die Entwicklung von Proteinliganden, die von der Natur in der Evolution selektioniert wurden.

Proteinstrukturen vergleichen: „Similarity Clustering“
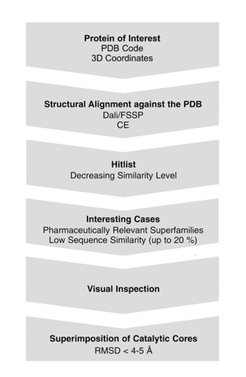
Bei Proteinen ist die räumliche Struktur in der Evolution stärker konserviert als die Aminosäuresequenz, und die Anzahl der in der Natur auftretenden Faltungstypen ist sehr begrenzt (etwa 1000). Diese Konservierung der räumlichen Struktur war das entscheidende Argument dafür, die Proteine hinsichtlich ihrer Liganden-bindenden Kernbereiche zu gruppieren. In diesem Ansatz werden die Liganden-erkennenden Kerne von Proteinen identifiziert und auf der Grundlage struktureller Ähnlichkeit sowie unabhängig von Sequenzähnlichkeit oder mechanistischen Argumenten zusammengefasst. Auf diese Weise erzeugen die Forscher einen „protein structure similarity cluster“ (PSSC). Die Strukturen von Ligandentypen, die an ein gegebenes Mitglied dieses Clusters binden, werden dann genutzt, um Liganden für andere Mitglieder des Clusters zu entwickeln [1]. Zur Identifizierung von PSSCs wurde die Strategie entwickelt, die in Abbildung 2 dargestellt ist.

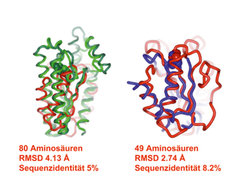
Die Strategie wurde erfolgreich angewendet, um einen PSSC zu identifizieren, der die Proteinphosphatase Cdc25A, die Acetylcholin-Esterase (AChE) und die 11-β-Hydroxysteroid-Dehydrogenase (11-β-HSD 1) umfasst (Abb. 3) – alle drei Enzyme sind wichtige Zielproteine in der medizinisch-chemischen Forschung. Bemerkenswert daran: Aufgrund der niedrigen Sequenzidentität in den Liganden-erkennenden Kernstrukturen dieser Proteine wären sie nach evolutiven Gesichtspunkten nicht gruppiert worden.
 11-β-HSD 1 und 2 (grün) und AChE (blau) gebildete „protein structure similarity cluster“.")
Da die genaue strukturelle Organisation der Bindungsstellen, das heißt ihre gebundenen Aminosäure-Seitenketten entscheidend für die Bindung von Liganden sind, bilden solche Ähnlichkeits-Cluster Hypothesen-erzeugende Werkzeuge, mit denen sich die Rückgrat-Strukturen potenzieller Liganden identifizieren lassen. Da die Bindungsstellen ganz verschieden sein können, ist es notwendig, Substanzsammlungen herzustellen, deren chemische Diversität der biologischen entspricht. Wenn biologisch vorvalidierte Ligandenklassen für ein Protein eines PSSCs identifiziert werden (beispielsweise aus Naturstoffklassen, jedoch nicht auf diese beschränkt), dann können nach ihrem Vorbild Substanzsammlungen hergestellt werden, die hohe Trefferquoten bei vergleichsweise kleiner Substanzbibliothek liefern.
Basierend auf dieser Idee wurde eine Sammlung von 147 Substanzen hergestellt, die von dem Naturstoff Dysidiolid, einem Hemmstoff der Cdc25A-Phosphatase, abgeleitet wurden. Die Substanzsammlung lieferte potente und selektive Inhibitoren für die anderen Mitglieder des PSSC mit einer Trefferquote von zwei bis drei Prozent. Darüber hinaus wurde dieser Ansatz genutzt, um Literaturdaten zu analysieren, die für unterschiedliche Substanzsammlungen publiziert worden sind. Die Analyse ergab, dass der von Waldmann gewählte Ansatz beispielsweise die Entwicklung von hoch affinen Agonisten des Farnesoid X-Rezeptors und die potenter Inhibitoren der Leukotrien-A4-Hydrolase ermöglicht hätte.
Strukturelle Klassifikation von Naturprodukten
Die Strukturen, die den in der Evolution selektionierten Naturstoffen (NPs) zugrunde liegen, definieren Voraussetzungen für die Bindung an Proteine: Denn diese Naturstoffe werden von Proteinen synthetisiert und sie üben ihre biologischen Funktionen oft durch Binden an Proteine aus. Daher bilden die Rückgrat-Strukturen von Naturstoffklassen die biologisch relevanten und vorvalidierten Regionen des chemischen Strukturraums, die von der Natur bislang ausgelotet wurden. Folglich werden Substanzsammlungen, die entworfen wurden, um Naturstoffklassen zu imitieren, hinsichtlich biologischer Aktivität angereichert sein.
Zur Analyse der Naturstoffstruktur wurde ein „cheminformatischer“ Ansatz entwickelt, der ein systematisches, strukturorientiertes Organisationsprinzip aller bekannten Naturstoffe zur Verfügung stellt und die Naturstoffe in ihrer Diversität vereinfacht und kategorisiert. Er stellt außerdem ein Hilfsmittel dar, um von den Naturstoffen abgeleitete und inspirierte Substanzsammlungen zu entwickeln. Diese strukturelle Klassifizierung von selektionierten Naturstoffen (SCONP) ist ein Hypothesen- und Ideen-erzeugendes Hilfsmittel, das strukturelle Verwandtschaft zwischen unterschiedlichen Naturstoffklassen in einer baumartigen Anordnung definiert [2].
Auf der Grundlage des „dictionary of NPs“, das zirka 170.000 Naturstoffe enthält, wurde der so genannte „NP scaffold tree“ entwickelt, in dem Naturstoffe anhand der ihnen zugrunde liegenden Rückgrat-Strukturen angeordnet sind (Abb. 4).

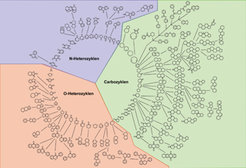
Hierarchische strukturelle Verwandtschaften basieren auf einem „parent scaffold“, das eine Substruktur darstellt, die in einem „child“ auftritt. Diese Anordnung führt zur Etablierung von strukturellen Genealogien. Die statistische Analyse der Daten, die für diese Klassifizierung herangezogen wurden, ergab, dass 52 Prozent aller Naturstoff-Rückgrat-Strukturen zwei bis vier Ringe enthalten und dass sie deutlich kleiner sind als die Vertiefungen in den Oberflächen von etwa 18.000 Proteinen. Damit lassen diese Strukturen ausreichende Möglichkeiten zur Erweiterung im Rahmen nachfolgender Synthesen zu. Die „cheminformatische“ Analyse ergab ebenfalls eine Zusammenstellung der Substituenten, die die Natur für die Auskleidung der NP-Rückgrat-Strukturen gewählt hat. Diese Daten sind nun für den Entwurf von Naturstoff-inspirierten Substanzsammlungen verfügbar.
Die systematische Anwendung des Naturstoffbaumes für die Zusammenstellung einer größeren Substanzbibliothek aus mehreren kleineren Substanzsammlungen sollte es ermöglichen, eine differenzierte, aber vergleichsweise kleine Suchbibliothek zusammenzustellen. Sie sollte zum einen vielfältig sein, da sie auf der Diversität basiert, die in der Natur gefunden wird, zum anderen angereichert an biologisch relevanten Mitgliedern, da die Rückgrat-Strukturen der individuellen Subbibliotheken biologisch vorvalidiert sind. Eine solche Substanzbibliothek sollte darüber hinaus – obwohl sie vergleichsweise klein ist – hohe Trefferquoten in unterschiedlichen biochemischen und biologischen Assays liefern.
Zusätzlich zu dieser natürlichsten Anwendung von SCONP sollte eine weniger offensichtliche und vielleicht weniger generelle, aber im Erfolgsfalle sehr wertvolle Anwendung des NP-Baums möglich sein. Hangelt man sich entlang biologisch vorvalidierter struktureller Äste innerhalb des Baumes von einem äußeren Ast zu strukturell weniger komplizierten Rückgrat-Strukturen auf einem inneren Ast über intermediär auftretende, natürlich vorkommende Rückgrat-Strukturen, so könnte das zu strukturell einfacheren Substanzklassen mit ähnlicher biologischer Aktivität führen (Abb. 5).

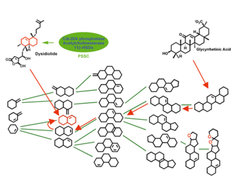
Am Beispiel des pentazyklischen Naturstoffs Glycyrrhetinsäure haben Waldmann und sein Team erstmals gezeigt, dass dies tatsächlich möglich sein kann. In silico-Entfernung der Substituenten ergab das grundlegende Rückgrat des Naturstoffs und ein Hangeln zu Rückgrat-Strukturen mit zwei anellierten Ringen führte zu Octahydronaphtalen-Strukturen. Bei der endgültigen Entscheidung für das Rückgrat zur Entwicklung einer Substanzsammlung wurde der SCONP-Ansatz mit der PSSC-Methode kombiniert. Die Glycyrrhetinsäure ist ein unspezifischer Inhibitor der 11-β-Hydroxysteroid-Dehydrogenasen und ist ein Mitglied des oben beschriebenen similarity clusters. Daher wurde nach Naturstoffen gesucht, die eines der anderen Mitglieder des Clusters inhibieren und im Naturstoffbaum auftreten. Dysidiolid erfüllt dieses Kriterium und die Identifizierung und Einordnung seiner Rückgrat-Struktur in den Ast des Baumes, durch den gehangelt wurde, führte zum Entwurf und zur Synthese einer spezifischen Octahydronaphtalen-Bibliothek.
Die Untersuchung von 162 Verbindungen dieses Typs ergab 30 11-β-HSD1-Inhibitoren mit IC50-Werten im Bereich 0.31 - 9.1 µM, davon zeigten vier Inhibitoren nanomolare Aktivität. Darüber hinaus wurden drei 11-β-HSD2-Inhibitoren identifziert. Die Inhibitoren waren aktiv in zellulären Assays, wie an einem Translokations- und einem Transaktivierungs-Assay gezeigt werden konnte.
Diese erfolgreiche experimentelle Verifizierung des weniger offensichtlichen „Hangelns“ entlang biologisch vorvalidierter Rückgrat-Strukturklassen belegt, dass der gewählte Ansatz in der Tat ein effizientes Werkzeug für die Entwicklung neuer Inhibitorklassen sein kann.
PSSC und SCONP als Leitprinzipien für die chemische Genomik
In der chemischen Genomik werden Klassen kleiner Moleküle für die Untersuchung der biologischen Funktion von Proteinfamilien eingesetzt. Gegenwärtig werden Proteinfamilien dabei meist auf der Grundlage mechanistischer und funktioneller Ähnlichkeit (z. B. Proteasen, Kinasen, Phosphatasen etc.) oder aber auf der Grundlage evolutiver Verwandtschaft (Sequenzhomologie und Identität, Proteinfamilien und Superfamilien) definiert.
Wie bereits beschrieben, bietet PSSC (Protein Structure Similarity Clustering) eine Alternative zur Gruppierung nach diesen Prinzipien, da es die strukturelle Ähnlichkeit in den Liganden-erkennenden Kernstrukturen als Maß für die Gruppierung von Proteinen zu Proteinfamilien nutzt. Daher könnte PSSC alternative Ansätze für das Studium biologischer Phänomene liefern. Insbesondere wenn dieses Clustern mit SCONP (Strukturelle Klassifikation von Naturprodukten) kombiniert wird, sollte die Methode neue Substanzklassen für die chemische Genomik beisteuern.
Die Dortmunder Forscher haben die Gültigkeit dieses Ansatzes belegt, indem sie zeigten, dass Mitglieder der Octahydronaphtalen-Bibliothek, die basierend auf dem SCONP-Ansatz entwickelt wurde, tatsächlich selektive Inhibitoren für 11-β-HSD 1/2, Cdc25A und Acetylcholinesterase (AChE) liefern. Im biochemischen Assay wurden Cdc25A-Inhibitoren mit 2,2 % Trefferquote und Inhibitoren der Acetylcholinesterase mit 1,8 % Trefferquote identifiziert. Mehrere dieser Inhibitoren waren 5- bis 10-fach selektiv für die jeweiligen Enzyme, die in dem Ähnlichkeitscluster zusammengefasst waren.
Da der als Leitmotiv dienende Naturstoff Dysidiolid ein Inhibitor der Phosphatase Cdc25A ist, wurde die Substanzsammlung ebenfalls auf Inhibitoren für unterschiedliche Phosphatasen untersucht. Die Suche ergab selektive Inhibitoren für Tyrosin- und Serin/Threonin-Phosphatasen unterschiedlichster biologischer Funktion (PTP1B, VHR, Cdc25A, PP1, MptpB und MptpA). Dabei beobachteten die Wissenschaftler hohe Trefferquoten von 1 bis 6,3 % und eine zumindest 5- bis 10-fache Selektivität.
Biologische Aktivität wurde in einem Fall für einen selektiven VHR-Inhibitor gezeigt, der die Entwicklung des kardiovaskulären Systems von Zebrafischembryos beeinflusste und zu reduziertem Herzschlag führte. Das zentrale Nervensystem und das optische System wurden nicht beeinflusst.
Diese Resultate belegen, dass die Anwendung von SCONP allein oder zusammen mit PSSC zu neuen Ansätzen führen kann, mit denen sich Substanzklassen für die Forschung in der chemischen Genomik entwickeln lassen (Abb. 6).